1. 그룹함수의 종류
1) count함수 (많이 사용)
테이블에서 조건을 만족하는 행의 갯수를 반환
1-2) 사용법
- '*'은 NULL을 포함한 모든 행의 갯수
- DISTINCT는 중복되는 값을 제외한 행의 개수
- 문자, 숫자, 날짜타입을 쓸수 있다.
예제1) 101번 학과 교수중에서 보직수당을 받는 교수의 수를 출력
SELECT COUNT(COMM)
FROM PROFESSOR
WHERE DEPTNO = 101;
※ 주의할점
집계함수끼리는 같은자리에 올 수 있지만 일반컬럼과 집계함수는 같은자리에 올 수 없다.
SELECT COUNT(*), COMM
FROM PROFESSOR
WHERE DEPTNO = 101 AND COMM IS NOT NULL;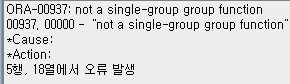
SELECT COUNT(*), SUM(COMM), AVG(COMM), MAX(COMM), MIN(COMM)
FROM PROFESSOR
WHERE DEPTNO = 101 AND COMM IS NOT NULL;
SUM은 합계값 리턴
AVG는 평균값 리턴
MAX는 최대값 리턴
MIN은 최소값 리턴이다.
2) AVG, SUM 함수 (많이 사용)
- 데이터타입은 NUMBER데이터 타입만 가능
예제) 101번 학과 학생들의 몸무게 평균과 합계 출력
SELECT SUM(WEIGHT), AVG(WEIGHT)
FROM STUDENT
WHERE DEPTNO = 101;
3) MIN, MAX 함수
예제) 102번 학과 학생중에서 최대 키와 최소 키를 출력
SELECT MAX(HEIGHT), MIN(HEIGHT)
FROM STUDENT
WHERE DEPTNO = 102;
2. 데이터 그룹 생성
1) GROUP BY절
- 특정 칼럼값을 기준으로 테이블의 전체 행을 그룹별로 나누기 위한 절
- 결과집합을 보기위한 기준
- GROUP BY절에 명시되지 않은 칼럼은 그룹함수와 함께 사용할 수 없다. (SELECT에 오려면 반드시 GROUP BY절에 명시되어 있어야함)
※ 규칙
- WHERE가 GROUP BY보다 빠르다.
- 반드시 컬럼 이름을 포함해야 하며 컬럼별명은 사용할 수 없음 (셀렉트보다 그룹바이가 빠르기 때문)
- SELECT절에서 나열된 컬럼 이름이나 표현식은 GROUP BY절에 반드시 명시
- GROUP BY절에서 명시한 컬럼 이름은 SELECT절에서 명시 안해도 된다.
예제)단일 칼럼을 이용한 그룹핑 // 교수테이블에서 학과별로 교수 수와 보직수당을 받는 교수 수를 출력
SELECT DEPTNO, COUNT(COMM), COUNT(*)
FROM PROFESSOR
GROUP BY DEPTNO
ORDER BY 1;
3) 다중 칼럼을 이용한 그룹핑
- 하나이상의 칼럼을 그룹을 나누고, 그룹별로 다시 서브그룹을 나눔
- 전체 교수를 학과별로 먼저 그룹핑한 다음, 학과별로 교수를 직급별로 다시 그룹핑 하는 경우
예제) 학과별로 소속 교수들의 평균급여, 최소급여, 최대급여를 출력
SELECT DEPTNO, POSITION, AVG(SAL), MIN(SAL), MAX(SAL)
FROM PROFESSOR
GROUP BY DEPTNO, POSITION;
예제2)전체 학생을 소속 학과별로 나누고, 같은 학과 학생은 다시 학년별로 그룹핑하여 학과와 학년별 인원수, 평균몸무게 출력, 평균몸무게는 소수점 이하 첫번째 자리에서 반올림
SELECT DEPTNO, GRADE, COUNT(*), ROUND(AVG(WEIGHT))
FROM STUDENT
GROUP BY DEPTNO, GRADE
ORDER BY 1,2;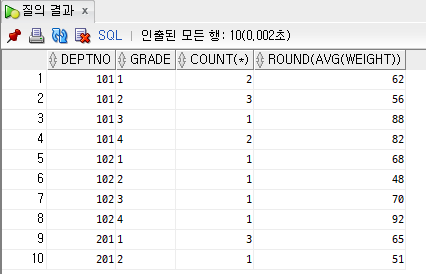
4) ROLLUP, CUBE 연산자
4-1) ROLLUP (정말 많이 씀)
- GROUP BY 절의 그룹 조건에 따라 전체 행을 그룹화 하고 각 그룹에 대해 부분합을 구하는 연산자
- GROUP BY 절에 칼럼의 수가 n개이면 ROLLUP 그룹핑 조합은 n+1개
- 부분합이라고 생각하면 편하다

예제) 소속 학과별로 교수 급여 합계와 모든 학과 교수들의 급여 합계 출력
SELECT DEPTNO, SUM(SAL)
FROM PROFESSOR
GROUP BY ROLLUP(DEPTNO);
예제2)
4-2) CUBE 연산자 (사용빈도가 낮음)
- ROLLUP에 의해 그룹 결과와 GROUP BY절에 기술된 조건에 따라 그룹 조합을 만드는 연산자
- GROUP BY절에 칼럼의 수가 n개이면 CUBE 그룹핑 조합은 2n개
- 부분합의 부분합이라고 생각하면 편함

5) GROUPING 함수
- 인수로 지정된 칼럼이 ROLLUP이나 CUBE 연산자로 생성된 그룹조합에서 사용되었는지 여부를 1 또는 0으로 반환
- 사용하면 0 아니면 1
6) HAVING절
- GROUP BY절에 의해 생성된 그룹을 대상으로 조건을 적용
6-1) HAVING절의 실행과정
- 테이블에서 WHERE절에 의해 조건을 만족하는 행 집합을 선택
- 행 집합을 GROUP BY절에 의해 그룹핑
- HAVING절에 의해 조건을 만족하는 그룹을 선택
예제) 학생수가 4명이상인 학년에 대해서 학년, 학생수, 평균키, 평균몸무게 출력
단, 평균키와 평균몸무게는 소수점 첫번째 자리에서 반올림 하고, 출력순서는 평균키가 높은 순부터 내림차순 출력
SELECT GRADE, COUNT(*), ROUND(AVG(HEIGHT)), ROUND(AVG(WEIGHT))
FROM STUDENT
GROUP BY GRADE
HAVING COUNT(*) >= 4
ORDER BY 3 DESC;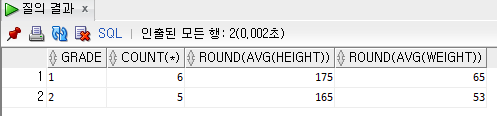
※ SQL 작성 순서
-- FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY
6-2) HAVING절과 WHERE절의 성능차이
- HAVING절 : 내부정렬 과정에 의해 그룹화된 결과집합에 대해 검색 조건 실행
- WHERE절 : 그룹화하기 전에 먼저 검색 조건 실행
7) 함수의 중첩
- 그룹함수의 결과를 다시한번 그룹함수에 넣은것
2. 조인(JOIN)
1) 개념 (합쳐지다)
- 하나의 SQL 명령문에 의해 여러 테이블에 저장된 데이터를 한번에 조회할수 있는 기능
- RDBMS의 표준 문법
- 두개이상의 테이블을 '결합'한다는 의미
2) 필요성
※ 조인을 사용하지않는 일반적인 예
- 학생에 대한 정보검색하는 단계 필요
- 학생 정보에서 소속학과번호 정보를 추출하여ㅓ 소속학과 이름을 검색하는 단계 필요


3) 칼럼이름의 애매모호성
3-1) 애매모호성 해결방법
- 서로 다른 테이블에 있는 동일한 칼럼 이름을 연결할경우 칼럼 이름앞에 테이블 이름을 접두사로 사용
테이블 이름과 칼럼 이름은 점. 으로 구분
- SQL명령문에 대한 구문분석 시간 줄임
예시)
DEPTNO칼럼이 STUDENT테이블과 DEPARTMENT테이블의 동일한 이름으로 정의되어 오류가 발생
그럴땐 칼럼이름 앞에 테이블 이름을 사용하면 애매모호성 문제가 해결
혹은 테이블 별명을 사용
4) 테이블 별명
테이블 이름이 너무 긴 경우 사용
- 테이블 이름을 대신하는 별명 사용 가능
- FROM절에서 테이블 이름 다음에 공백을 두고 별명 정의
- 별명을 지정한 테이블 이름과 별명을 혼용할 수 없다.
5) AND연산자를 사용한 검색 조건 추가
예제1) 전인하 학생의 학번, 학과번호, 학과 이름을 조회
SELECT STUDNO, NAME, S.DEPTNO, DNAME
FROM STUDENT S, DEPARTMENT D
WHERE S.DEPTNO = D.DEPTNO
AND NAME = '전인하';
예제2) 전인하 라는 이름을 가지는 학생의 학번, 이름, 담당교수번호, 담당교수 이름을 조회
SELECT STUDNO, S.NAME, S.PROFNO, P.NAME P_NAME
FROM STUDENT S, PROFESSOR P
WHERE S.PROFNO = P.PROFNO
AND S.NAME = '전인하';
'DATABASE' 카테고리의 다른 글
| 23-02-06(1) 데이터베이스 ( (0) | 2023.02.06 |
|---|---|
| 23-02-03(1) 데이터 베이스(JOIN, 단일행 서브쿼리) (0) | 2023.02.03 |
| 23-02-01 (1) 데이터베이스 (날짜함수, 그룹함수) (0) | 2023.02.01 |
| 23-01-31 (1) 데이터베이스 (NULL, SQL연산자, 날짜함수) (0) | 2023.01.31 |
| 23-01-30(1) 데이터베이스 (데이터 타입, Where절을 이용한 조건 검색) (0) | 2023.01.30 |